
I deleted my source code
This blogpost relates to the code in this Github repo.
Clean code. SOLID principles. Meaningful variable names. Small functions. We’ve built an entire discipline around making code readable, maintainable, and elegant. And for good reason. We have to read it, understand it. We review it, debug it, extend it, onboard onto it.
But what if we stop reading it?
The human is leaving the loop
AI-generated code is already everywhere. Claude autocompletes your functions. Agents write entire files. The code works, the tests pass. But then, we “cleanup” the code that AI has written. We rename variables, rearrange the structure, change “meaningless” details.
We’re heading toward a world where more and more code is written by machines, and humans have to read or write less of it. In that world, who is clean code for?
Not the machine. It doesn’t care about your variable names. It doesn’t need small functions to understand the logic. It will happily generate an 800-line controller and move on. The conventions we’ve spent decades refining are a human interface. And the human is leaving the loop.
Today, code is the critical point — the place where quality is enforced, where reviews happen, where knowledge lives. Everything before it (requirements, specs) is treated as secondary. Everything after it (runtime, infrastructure) is automated away.
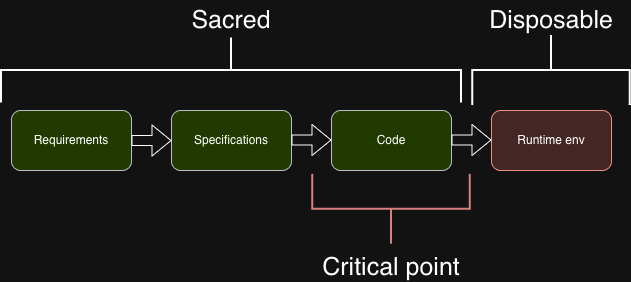
But what actually matters are the decisions:
- What is the API contract
- What happens when a parent record is deleted
- What validation rules do we have
- Whether partial updates use
nullto mean “clear this field” or “I didn’t send this field”
The code is just one expression of those decisions — and increasingly, not one that anyone needs to maintain.
This raised an interesting question:
What if the code was a build artifact, like a compiled binary, and the spec was the source?
I built a proof of concept to push that idea to its limit.
The experiment
A Symfony project with no source code. The src/ dir only contains some empty subdirs. Yet it is a fully functional TODO app API. The repo contains:
- Spec files — A plain language description of a feature. Containing business logic, and some technical spec details.
- A SQL schema — the database structure (also written by AI, of course)
- A large set of PHPUnit tests — the contract, defined as HTTP requests and assertions
In our CI pipeline, an AI agent reads all of it, generates the implementation, runs the tests, fixes potential failures, and continues until everything is green. The generated code never gets committed. It’s produced on demand, in CI, and thrown out on the next build.
The tests included in the repository might even be overkill. Theoretically, if a specification is detailed enough, a separate, independent CI pipeline could generate the test suite from those specifications. Then the tests, without having access to the code, or the code having access to the tests, should still fully pass.
The benefit of this approach, is that our code magically improves. As AI agents improve, and new models are released, our code massively improves too. Its regenerated on every build. There is no legacy code. If there is a new best practise, or even a new framework, we can just add it to the spec and regenerate.
Imagine if we add a new feature that fundamentally changes the API. We don’t have to worry about how the implementation will work with the old code. The new code will support this feature from the ground up.
The sample domain is a task management API — Symfony 8, Doctrine, PostgreSQL — built incrementally in five commits. Each one follows the same pattern: write a spec, write tests, extend the schema.
Commits
1. Basic task management — The foundation. CRUD endpoints for tasks with a status lifecycle (todo → in_progress → done), validation rules, and response shapes. One spec file, one test file, one schema. The agent generated the full Symfony implementation: entities, controllers, repositories, and passed every test.
2. Subtask support — Extended the existing spec and tests rather than adding new files. Added parent_id, one-level nesting, cascade deletes, and a key business rule: a parent task can’t be marked done while it has open subtasks. The agent regenerated the entire codebase and passed all tests on the first run.
3. Comment support — A new entity, new spec, new test file. Append-only comments on tasks, with cascade deletes. Straightforward, but the first time the agent had to generate code that interacts across two entities.
4. Audit logging — The interesting one. An activity log tracking creates, updates, and deletes across the entire system, tasks, subtasks, and comments, all scoped to the top-level task. A cross-cutting concern: the agent had to wire logging through every existing endpoint without breaking anything.
5. Performance improvement — Just 7 lines added to the conventions spec. Tells the agent to use standard Symfony conventions and not inspect config files. A “performance improvement” for the agent, not the generated code, reducing wasted time exploring the project structure.
Where the real work happens
The interesting part wasn’t the code generation. It was the spec writing.
During the writing of the spec i had to make some specific decisions. Like, what is the response shape for validation errors?
These are decisions we normally make mid-implementation, semiconsciously, without writing them down. Here, I had to make them explicit and upfront. And I kinda think that’s actually where they belong.
Interesting thoughs
We are obviously not at the phase where you will delete your entire src/ dir, unlike the title of the post. But there are some interesting things to note.
Debugging changes shape. When a test fails, there’s no point fixing the generated code. It’ll be thrown away next run. The only meaningful fix is improving the spec or the test. You stop debugging implementations and start debugging intentions.
The code is non-deterministic. This is an obvious one. Run the generation twice and you get different variable names, different structure, sometimes different architecture entirely. Both versions pass the tests. Both are “correct.” You can’t diff two runs and expect stability.
Spec completeness is the new bottleneck. If your tests don’t assert that deleting a subtask should not delete its parent, the agent might generate code where it does, and the tests will pass. An incomplete spec produces code that is technically correct but behaviourally wrong.
That’s always been true in software. It just hits differently when the test suite is the only thing standing between the spec and production.
Why this matters
Most knowledge in a codebase is implicit. Remember that edge case bug you fixed? The fix lives in the codebase, and was probably not retroactively added to the initial feature spec afterwards. By result, you existing spec is useless.
A perfect spec, even in todays world, should mean you can rebuild the complete application, end to end, from scratch, without having to look at the existing codebase.
In the spec-driven model, the knowledge lives in the spec and the tests. The code is derived. Delete it and regenerate, different code, same behavior. The knowledge survives because it was never in the implementation to begin with.
The critical point moves. Code becomes more disposable. The spec becomes more sacred.
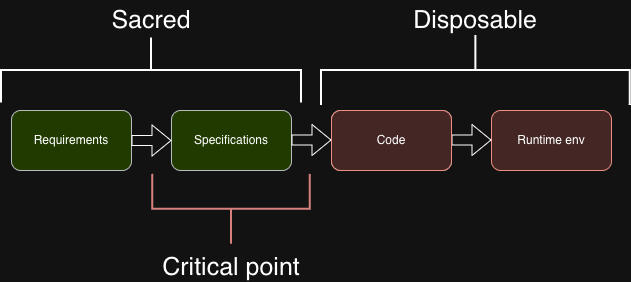
“AI writes code for us” is the shallow version. The deeper version is: the value moves from the implementation to the specification. The developer who writes a precise, testable, complete spec will produce better software than the one who writes clever code — not because the spec generates the code (though it can), but because a precise spec forces every decision to be made explicitly, documented, and verifiable.
Most teams already sense this. It’s why we write acceptance criteria. It’s why we write integration tests. It’s why the best tech leads spend more time on requirements than on pull requests. Spec-driven development just follows that intuition to its logical end.
Whether you ever adopt this workflow or not, the experiment leaves you with one useful question:
If your specs aren’t precise enough to generate correct code from, are they precise enough to build correct code from by hand?
Conclusion
While the demo project I used here is a best-case scenario, it’s not impossible to imagine a future where the spec will become more important than the code.
Imagine if you can generate a full, feature complete spec from an existing codebase. Replatforming a legacy system becomes a matter of tokens, not months of development. You can switch frameworks, languages, architectures, with the push of a button.
The classic development workflow we all know and loved, is disappearing fast. We will no longer care about the nitty gritty details of how the code works. We will only care that it does.
{kind=link}